Writing Deterministic & Performant Specs with Capybara
Acceptance tests are a great tool for guiding [outside in testing] and defining application behavior. Unfortunately they are also notoriously slow and often brittle. At Carbon Five we usually use Capybara to drive our acceptance tests (either directly in RSpec feature specs or within Cucumber steps) so let’s explore some ways we might accidentally write bad tests and how to avoid them.
If we are using Capybara’s RackTest driver things are fairly simple. The driver doesn’t support JavaScript so we have a single Ruby process running our tests and performing synchronous requests against our application. Unfortuanetly this is usually insufficient to exercise client side application behavior which requires running JavaScript. (We’ll leave discussion of if it is appropriate to exercise both client and server side behavior in a single test for another post.) Instead of RackTest we usually use the Poltergeist driver which provides a headless WebKit browser capable of executing JavaScript served by our app.
For these examples we use RSpec feature specs which use the Capybara DSL directly. In large apps we might find the same behaviors wrapped in Cucumber step definitions or inside custom RSpec matchers. Those may make if more difficult to spot poorly performing assertions.
Set up
To get things started here is a simple page with some asynchronous behavior. It displays a list of role playing game characters and allows the user to filter the set to show only characters of a specific class: fixture.html
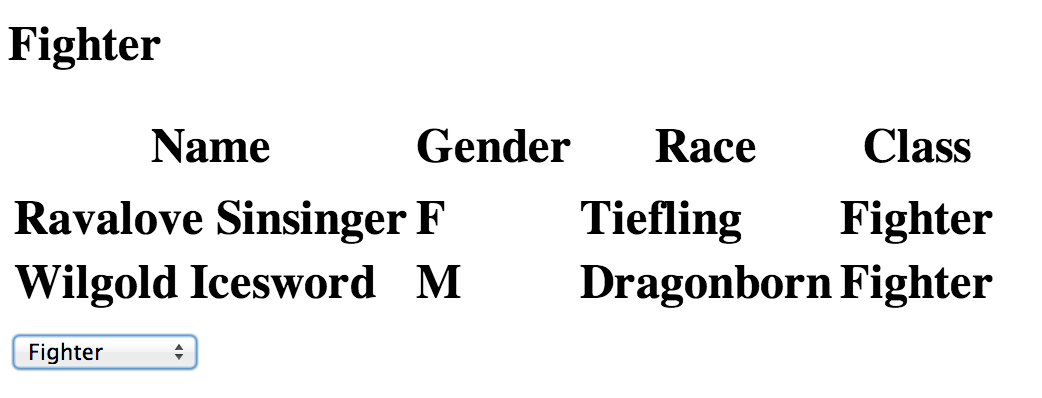
This fixture page and the tests shown here are available at github.com/carbonfive/capybara_race_conditions
We can pretend that this data set is loaded asynchronously from some remote backend and so we define LOAD_CONTENT_DELAY in the page’s JavaScript to simulate the time required to update the characters list when a new filter setting is applied.
When our filter selection changes we want to clear the list currently on the page. That doesn’t require a round trip to the backend but still takes a little time. We define CLEAR_CONTENT_DELAY to give us some control over that delay so that we can see how the timing of that JavaScript interacts with our Ruby specs.
Let’s start with a simple spec:
Now we know that when the page loads it will not contain any visible content until our 1 second of artificial delay finishes. However this spec will still pass because Capybara’s content matchers will retry (for up to Capybara.default_wait_time seconds) before failing.
› rspec spec/example_spec.rb:9
Run options: include {:locations=>{"./spec/example_spec.rb"=>[9]}}
.
Finished in 2.37 seconds
1 example, 0 failures
So far so good. On this machine just visiting the page in a spec takes ~1.33s and we have an additional 1s delay on the page so our simple spec is reasonably fast.
Race conditions
Let’s interact with the page:
Now we have some potentially misleading specs. These pass but might not prove that the page behaves we expected because we can not guarantee the order of execution of our Ruby spec operations and the JavaScript in the Capybara driver.
Conveniently the page adds a loading class to the characters list while we wait for changes in our filter selection to be applied. We can just wait until the list finishes loading and then make our assetion right?
Uh oh. Here again we could see unpredictable behavior depending on the order in which our test runs relative to the page. With nice long artificial delays like we have in this example the results should be stable but a real application could see tests fail from minor changes to response times.
We might be able to synchronize our test with the page Javascript using Capybara’s evaluate_script or execute_script actions. However then we need to start writing our own synchronize blocks to wait for the exepected conditions and we’re starting to couple our acceptance test to implementation details of the page.
There must be something we can do using just the visible page interface:
Finally we should have a safe assertion because we’re looking for a persistent change on the page instead of a transient state (like the loading class) which would might miss entirely. Our test is not coupled to our JavaScript implementation but it does depend on the order of some DOM updates. Depending on the app this might be more or less stable than some state exposed by the page’s implementation.
Performance
Capybara’s content matchers will retry until they timeout or are satisfied. We want to design our tests to succeed quickly and not wait for a timeout in order to pass. When we know that we don’t need to wait for asynchronous behavior we can use all to check the current state of the page without any retrying.
› rspec spec/example_spec.rb:81
Run options: include {:locations=>{"./spec/example_spec.rb"=>[81]}}
has_content? in (1.052696)
.has_no_content? in (0.003708)
.has_content? timeout in (2.014941), Capybara.default_wait_time=2
.all matcher in (0.001620)
.
Finished in 4.43 seconds
4 examples, 0 failures
Here we have one test which is unavoidably slow as it waits for actual changes on the page and one which we should try to rewrite so as to not always wait for a full timeout duration before succeeding.
Capybara anti-patterns
Given all of the above there are a couple of anti-patterns we can try to watch for when writing specs which use Capybara.
Accidental retries
As we write and re-write tests it can be easy to unintentionally mix retrying content matchers and immediate finders. This can lead to very slow tests.
› rspec spec/example_spec.rb:114
Run options: include {:locations=>{"./spec/example_spec.rb"=>[114]}}
iterating test passed in (64.640525)
.
Finished in 1 minute 6.98 seconds
1 example, 0 failures
Here switching to cell.text.include? 'Hollyonna Madwar' would reduce the test run time from 64.64 seconds to 2.45.
Inverted matchers
Custom matchers make it easier to make assertions using our domain language but it may not be reasonable to allow them to be inverted.
› rspec spec/example_spec.rb:128
Run options: include {:locations=>{"./spec/example_spec.rb"=>[128]}}
to have_character in (1.041502)
to_not have_character in (2.028751)
.
Finished in 4.39 seconds
1 example, 0 failures
Here we could implement match_for_should and match_for_should_not instead of match and raise in match_for_should_not to prevent misuse of the matcher.
Conclusion
Equipped with an basic understanding of how Capybara matchers work we should be able to write tests which execute as quickly as our site performance allows and which provide reliable, meaningful, and deterministic results.
I have found all of the mistakes above in my own acceptance test suites and correcting them has cut minutes off my test run times. How do your test suites look?