
Node.js in Production
When running a node application in production, you need to keep stability, performance, security, and maintainability in mind. Outlined here is what I think are the best practices for putting node.js into production.
By the end of this guide, this setup will include 3 servers: a load balancer (lb) and 2 app servers (app1 and app2). The load balancer will health check and balance traffic between the servers. The app servers will be using a combination of systemd and node cluster to load balance and route traffic around multiple node processes on the server. Deploys will be a one-line command from the developer’s laptop and cause zero downtime or request failures.
It will look roughly like this:
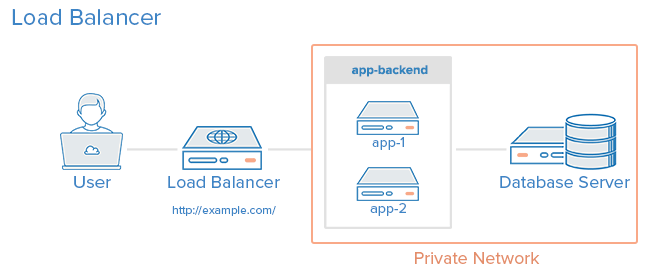
Photo credit: Digital Ocean
How this article is written
This article is targeted to those with beginning operations experience. You should, however, at least be basically familiar with what a process is, what upstart/systemd/init are and process signals. To get the most out of it, I suggest you follow along with your own servers (but still using my demo node app for parity). Outside of that, there are some useful configuration settings and scripts that should make for good reference in running node.js in production.
The final app is hosted here: https://github.com/dickeyxxx/node-sample.
For this guide I will be using Digital Ocean and Fedora. However, it’s written as generically as possible so there should be value here no matter what stack you’re on.
I will be working off of vanilla Digital Ocean Fedora 20 servers. I’ve tested this guide a few times, so you should be able to follow along with each step without a problem.
Why Fedora?
All Linux distros (aside from Gentoo) are moving to systemd from various other init systems. Because Ubuntu (probably the most popular flavor in the world) hasn’t yet moved over to systemd (they’ve announced they will), I felt that it would be inappropriate to teach Upstart here.
systemd offers some significant advantages over Upstart including advanced, centralized logging support, simpler configuration, speed, and way more features.
Install Node.js
First thing you’ll need to do on the server is to set it up to run node. On Digital Ocean, I was able to get it down to just these 4 commands:
This installs node from yum (which might install an old version), then the awesome n package to install/switch node versions. Finally, n installs the latest stable build of node.
From here, run # node --version and you should see it running the latest node version.
Later we’ll see how to automate this step with Ansible.
Create web user
Because it is insecure to run your application as root, we will create a web user for our system.
To create this user: # useradd -mrU web
Adding the application
Now that we’ve added node and our user we can move on to adding our node app:
Create a folder for the app: # mkdir /var/www
Set the owner to web: # chown web /var/www
Set the group to web: # chgrp web /var/www
cd into it: # cd /var/www/
As the web user: $ su web
Clone the sample hello world app repo: $ git clone https://github.com/dickeyxxx/node-hello-world
It consists of a very simple node.js app:
Run the app: $ node app.js.
You should be able to go the server’s IP address in the browser and see the app up and running:
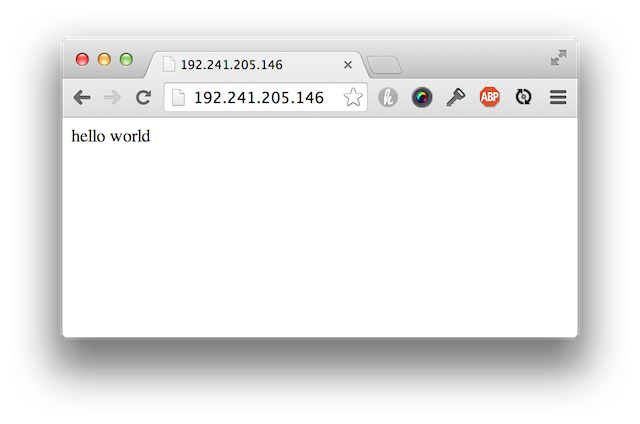
Note: you may need to run # iptables -F to flush the iptables as well as firewall-cmd --permanent --zone=public --add-port=3000/tcp to open the firewall.
Another Note: This runs on port 3000. Making it run on port 80 would be possible using a reverse proxy (such as nginx), but for this setup we will actually run the app servers on port 3000 and the load balancer (on a different server) will run on port 80.
systemd
Now that we have a way to run the server, we need to add it to systemd to ensure it will stay running in case of a crash.
Here’s a systemd script we can use:
Copy this file (as root) to /etc/systemd/system/node-sample.service
Enable it: # systemctl enable node-sample
Start it: # systemctl start node-sample
See status: # systemctl status node-sample
See logs: # journalctl -u node-sample
Try killing the node process by its pid and see if it starts back up!
Clustering processes
Now that we can get a single process running, we need to use the built-in node cluster which will automatically load balance traffic to multiple processes.
Here’s a script that you can use to host a Node.js app.
Simply run that file next to app.js: $ node boot.js
This script will run 2 instances of the app, restarting each one if it dies. It will also allow you to perform a zero-downtime restart by sending SIGHUP.
Try that now by making a change to the response in app.js. You can see the server update by running: $ kill -hup [pid]. It will gracefully restart by restarting one process at a time.
You’ll need to update the systemd configuration if you want it to boot the clustered version of your app as opposed to the single instance once. Also, if you add an ExecReload=/bin/kill -HUP $MAINPID attribute to your systemd config, you can run # systemctl reload node-sample to do a zero-downtime restart!
Here’s an example of the node cluster systemd config:
Load Balancing
In production you’ll need at least 2 servers just in case one goes down. I would not deploy a real system to just a single box. Keep in mind: boxes don’t just go down because they break, perhaps you want to take one down for maintenance? A load balancer can perform health checks on the boxes and if one has a problem, it will remove it from the rotation.
First, setup another Node.js app server using all of the previous steps. Next create a new Fedora box in Digital Ocean (or wherever) and ssh into it.
Install haproxy: # yum install haproxy
Change /etc/haproxy/haproxy.cfg to the following (replacing the server IPs with your app IPs):
Now restart haproxy: systemctl restart haproxy
You should see the app running on port 80 on the load balancer. You can also go to /haproxy?stats to see the HAProxy stats page. Credentials: (my_username/my_pass)
For more information on setting up HAProxy, check out this guide I used, or the official docs.
Deploying your code with Ansible
Now most production guides would stop here, but I don’t think this is a complete setup, you still need to do a deploy! Without a deploy script, it isn’t a terrible process to update our code. It would look something like this:
- SSH into app1
cd /var/www/node-hello-worldgit pullthe latest codesystemctl reload node-sampleto restart the app
The major downside is that we have to do this on each server, making it a bit laborious. Using Ansible we can push our code out from the dev machine and properly reload the code.
Ansible tends to scare people. I think people assume it’s similar to complicated tools like Chef and Puppet, but it’s a lot closer to Fabric or Capistrano. It basically just ssh’s into boxes and runs commands. No clients, no master server, no complicated cookbooks, just commands. It does have features that make it great at provisioning too, but you can just use it to deploy code if you wish.
Here’s the Ansible files needed if you’d like to deploy code like this:
Run it with the following from your dev machine (make sure you installed Ansible): ansible-playbook -i production deploy.yml
That production file is called an inventory file in Ansible. It simply lays out the hostnames of all the servers and their role.
The yml file here is called a playbook. It defines the tasks to run. In this case, it gets the latest code from github. If there are changes, it calls the ‘notify’ task that will reload the app server. If there are no changes, that handler does not get called. If you wanted to also say, install npm packages, you could do that here as well. Make sure you use npm shrinkwrap if you don’t check your packages into the repo, by the way.
Note: if you want to pull down a private git repo, you’ll need to set up SSH Agent Forwarding.
Ansible for Provisioning
Ideally, we would have the app server building part automated so we don’t have to go through these steps every time. For that we can use the following Ansible playbook to provision the app servers like we did manually before:
Run it like so: ansible-playbook -i [inventory file] app.yml.
Here is the same for the load balancer.
Final app
Here’s the final result of all these steps. As it mentions, updating the inventory file, running the provision and deploy steps should built out a full app automatically.
Staging?
Making other environments is easy. Simply add a new inventory file (ansible/production) for staging and start referencing it when calling ansible-playbook.
Testing
Test your setup. If for no other reason, it’s really fun to try to find ways to knock your cluster offline. Use Siege under load test mode. Try sending kill -9 to various processes. Knock a server offline. Send random signals to things. Run out of disk space. Just find things you can do to mess with your cluster and ensure that availability % doesn’t drop.
Improvements to be made
No production cluster is perfect, and this is no exception. I would feel pretty comfortable rolling this into production, but if I wanted to harden it further, here’s what I would do:
HAProxy Failover
Right now HAProxy (while stable) is an SPOF. We could change that with DNS Failover. DNS Failover is not instantaneous, and would result in a few seconds of downtime while DNS propogates. I am not really concerned about HAProxy failing, but I am concerned about human error in changing LB config.
Rolling deploys
In case a deploy goes out that breaks the cluster, I would setup a rolling deploy in Ansible to slowly roll out changes, health checking along the way.
Dynamic inventory
I think others would rate this higher than myself. In this setup you have to commit the hostnames of the servers into the source code. You can configure Ansible to use dynamic inventory to query the hosts from Digital Ocean (or other provider). You could also use this to create new boxes. Really though, creating a server in Digital Ocean isn’t the most difficult thing.
Centralized Logging
JSON logging is really the way to go since you can easily aggregate and search through the data. I would take a look at Bunyan for this.
It’d be nice if the logs for all of this were drained to one queryable location. Perhaps using something like Loggly, but there are lots of ways to do this.
Error Reporting and Monitoring
Again, lots of solutions for error reporting and logging. None that I’ve tried on node I have really liked though, so I’m hesitant to suggest anything. Please post in the comments if there’s a solution to either you’re a fan of.
For more tips, check out the awesome Joyent guide on running Node.js in production.
There you have it! This should make for a simple, stable Node.js cluster. Let me know if you have any tips on how to enhance it!