Applying Functional Programming Principles To Your Rails Codebase
All the programmers around me seem to have very strong opinions about functional programming. The Internet certainly loves to talk about it. Some of the concepts are interesting – but many of them (at first) don’t seem to apply for those of us writing database-fronting web applications. What can we apply from a world in which side effects are shunned if the majority of what our application is doing is getting stuff out of a database for display on a web page?
In this article, I’ll share some of the lessons I’ve learned writing programs in a functional style using other languages and how these lessons apply to problems of testability, predictability, and parallelism in the regular ‘ole web application code we’re writing today. I’ll show you how you can increase the quality of your existing application by introducing stateless functions that interact with the state-manipulating stuff you’re already familiar with (and have already written). This article is geared towards web application development in the real world; don’t fret, the word “monad” does not appear anywhere on this page.
Identifying the problem
Those of you who have ever used a cheap calculator – or perhaps the one provided by your OS (the kind with a “C” button) have already felt the pain of relying on implicit, hidden state. As you find yourself mashing the C-button on your calculator in an attempt to revert back to a state in which you can trust the results of the operations you’re asking it to perform – think about what it even means to perform an operation like “+ 9”. Add nine to what?, you may be thinking, before pushing the C-button a dozen times.
To illustrate my point, we’ll write code representing the behavior of our aforementioned cheapo calculator. It permits the user to do things by calling a method (representing an operation, like add or divide), followed by a number. The operation is performed against the internal state of the StatefulCalculator (the @total), which is then replaced by the result.
We’ll write some specs to demonstrate some of the gotchas of testing functions that rely on hidden, mutable state. In these examples, think of the before(:all) as an analog to several presses of our calculator’s C-button; we’re going to create a new instance of the StatefulCalculator before each test – effectively wiping out any long-lived state.
The burden of managing this state placed on the developer allows for the introduction of subtle bugs during test. Did you spot the bug in the test suite I wrote for the StatefulCalculator? It becomes noticeable when I write a test for the div method:
We run the suite and our division test fails – we expected 5 and got 14. But why? The use of before(:all) instead of before(:each) meant that we didn’t blow away our StatefulCalculator between tests. The calculator already had a total of 18 before hitting out division-test. By forgetting to destroy and re-create our calculator between test runs, our program behaved in a manner we didn’t expect.
This problem of predictability is exacerbated when code have stateful dependencies:
The NumberCruncher consumes the functionality of an injected dependency; it uses its add method to reduce an array of numbers into a single value. Our implementation of the crunch method is naive in that we assume that the @calculator has been given to us in a reset state. This places burden on the caller and allows for the introduction of subtle, state-related bugs:
Assuming the value of req[“arrays_to_crunch”] is [[1, 2, 3], [4, 5, 6]], the value of @sums will be [6, 21]. This is because a single StatefulCalculator was shared amongst both instances of NumberCruncher; the implementation of NumberCruncher assumed a clean slate, and behaved in an unpredictable manner when that assumption was not valid.
Prescriptive advice: 5 lessons for upping the quality of your Rails codebase
Lesson 1: Move side effect-free functionality into class methods (or module functions)
Look to identify bits of stateless code in your codebase that can be factored into modules and classes that can then be tested in isolation. In digging through a client project, I recently found a Resque job that was a good candidate for this type of refactor:
I identified the block being passed to select as a piece of functionality that could be rewritten as a stateless function and added it a new class, Prunable:
The methods of the Prunable class can now be used across a variety of contexts (pruning S3 images, SoundCloud tracks, etc.), and their stateless nature allows them to be tested with ease. Look to repeat this process throughout your codebase – you’ll end up with a toolbox of reusable functions whose behavior is easy to understand and simple to test.
Lesson 2: Write table-based unit tests for your stateless functions
Stateless functions (whose output depends only on their input) are perfect candidates for table-based unit tests. Think of these “tables” as a spreadsheet of values that your functions will consume. The following represents a table of inputs (columns x and y) that are passed to our function (which is supposed to be computing the absolute value of the sum of our two inputs).
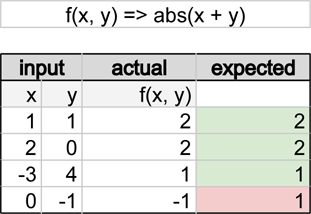
Functionally, these tests don’t differ from BDD-style unit tests, but they are more concise when testing that various permutations of inputs map to certain outputs (which is all that a stateless function does, really).
So when testing stateless functions, avoid doing this:
…and build yourself a table of inputs and outputs instead:
By removing much of the cruft that comes with permuting inputs in different describe blocks, the tests for your stateless functions become much shorter and are easier to read.
Lesson 3: Build an “imperative shell” around your stateless functions (nod to G. Bernhardt)
Side effect-free functions can live alongside regular Ruby code; it’s not an all-or-nothing approach. In a Rails application, this integration happens in an introduced abstraction layer that straddles the gap between stateless and state-manipulating code. This service will do little more than broker data between the side effect-heavy parts of my application (ORM, SendGrid, etc.) and my stateless functions.
This pattern enables us to keep as many of functions pure as possible, performing all IO in the service class. Mocking the service’s dependencies becomes less interesting; its role is only to coordinate between other, heavily unit-tested components in our application. I advocate that you forgo unit-testing the service entirely, instead relying on your integration tests to make sure it’s doing its job.
Lesson 4: Stateless functions make it (a little) easier to parallelize work
If your functions are stateless, you can distribute their execution across several threads without worrying about having to build mechanisms to coordinate writes to shared memory. This is because there is no mutation of shared memory taking place; each function call is independent from each other function call.
As an example, let’s use a single instance of StatefulCalculator to add together all numbers between 1 and 256. We’ll distribute this operation across 16 threads, using JRuby 1.7.10. In the block passed to each thread we will call the add method on the StatefulCalculator in its outer scope:
The StatefulCalculator is not threadsafe, causing us to get different results from each subsequent run. Why is this the case? The add method contains no synchronization logic; threads running in parallel can mutate the state of the @total between the time that the method reads a @total, adds to that value, and writes it back. This problem could be masked by writing some synchronization code or by instantiating a new StatefulCalculator in each thread (thereby avoiding the problem of sharing state across threads) – but we can do better than that. Let’s use the stateless version of our add method in each thread and then combining each thread’s results after completion:
Behold! Our result does not change across runs. By virtue of the StatelessCalculator’s add method being stateless, it is by definition threadsafe. Our threads aren’t relying on shared state (they simply operate on a slice of our range and return their result) and thus there is no synchronization logic to implement.
Lesson 5: Don’t unnecessarily add mutable state to your application
I have seen (and written) code that looks like this more often than I’d like to admit:
Aside from being a confusing API (the caller needs to do many things in order to import some RSS content), the usage of instance variables @articles and @result allow for invalid combinations of state:
After setting articles to a new value, other_rss_content, the value returned by a call to result remains unchanged and our program is in an invalid state until we call the import method.
We should rewrite our class to reflect the fact that we we don’t care about the state of the importer between the point at which we give it some articles to import and the time we call the import method. This simplifies the API, and reduces the possibility of getting ourselves into an invalid state as demonstrated above.
Summary
I hope that by this point you’ve seen the benefit that stateless functions provide in terms of testability, predictability, and their ability to be parallelized. We have demonstrated that stateless and state-manipulating parts of your codebase can live side-by-side in our new service abstractions which can be introduced to your existing codebase in an incremental fashion. I encourage you to play around with these concepts; I hope they have as much of a positive impact on my development practices as they do for yours.
Contact info
Follow me on Twitter @lasericus