
Evented Rails: Decoupling Complex Domains in Rails with Domain Events
In our last Domain-Driven Design discussion, we learned how to group similar business components into application Bounded Contexts, which were separated folders in our Rails apps. This segregated cohesive groups of application code into separate folder structures (bounded contexts), and gave us a jumping-off point to drawing more explicit boundaries between domains in our monolith. Now it’s time for us to re-think how to communicate from one context to another. Here’s how:
Decoupling bounded contexts with Domain Events
As a DDD design principle, we strive to keep bounded contexts isolated from other bounded contexts. This means that, as much as possible, we will try to insulate the internal workings of each module from other modules in the wild. This method of hiding is often achieved via the use of Domain Events.
What is a Domain Event?
A domain event is a recorded property in the system that tracks an action that the system performs, and the factors that lead to its creation. Events are simply the verbs that show up in your domain!
Let’s imagine Domain Events in the context of a sample app in which we are building a software service that allows passengers to request trips with drivers. Here are a few domain events that might occur in the workflow:
- A passenger requests a ride
- A driver receives a notification that she is to drive to the passenger
These events can be low-level system events too, such as:
- The system routing engine processes a navigation plan
- The financial transaction system charges a credit card
Let’s come up with a list of the domain events in our system. For the sake of simplicity, we’ll focus on one interaction that we have in our app – the act of hailing a driver from the passenger mobile app. In it, there are two domain events that happen – the passenger requests a ride, and the system routes a driver to the passenger.
| Context | Event Name | Event Parameters | Definition |
|---|---|---|---|
| Passenger Experience | ride_requested |
passenger_id, coordinates |
A passenger requests a ride to a destination |
| Routing (Navigation) | driver_routed |
driver_id, passenger_id, itinerary_id |
The system has routed a driver to pick up a passenger, with a generated itinerary |
How we used to do it
Here, we pick the Passenger::FindDriverMatch service object, which is invoked from a network request from the passenger over their mobile device. This service then must coordinate with the Routing domain in the system that routes a driver to his or her location.
In this first implementation, following typical Ruby conventions, we see how we might normally have coded up this implementation in our app:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| module Passenger | |
| class FindDriverMatch | |
| def call(passenger, ride_requirements) | |
| # Call another part of the system that has to do with routing | |
| # but requires deep internal knowledge of that code! | |
| driver = Routing::FindDrivers.new(passenger).call | |
| .select! { |d| d.meets?(ride_requirements) && d.matches_some_deeply_specific_thing? } | |
| .sample | |
| if driver | |
| Routing::NotifyDriver.new.call(driver) | |
| # Inform the passenger that the driver is on their way | |
| Passenger::SendDriverArrivalNotification.new.call(passenger, driver) | |
| else | |
| # Inform the passenger that no driver is available at this time. | |
| Passenger::SendRideUnavailableNotification.new.call(passenger) | |
| end | |
| end | |
| end | |
| end |
In fact, calling the code this way requires that we know an awful lot about the code “on the other side” in the other domain. While we’ve done a lot of great organization and packaged domain-specific code into domain-oriented modules, we find that the Passenger context still must know a lot about the deep internal implementation details of the Routing context. This increases the coupling between the two objects.

- We needed to know that there existed a
Routing::FindDriversservice somewhere in theRoutingmodule. - We must know that
Routing::FindDriversexposes acallmethod that returns a list of drivers. - We also must know that each Driver implements a
meets?method and amatches_some_deeply_specific_thing?method. - We must know that drivers are chosen at random via the
samplemethod. - We must know that drivers must be notified when selected via the
Routing::NotifyDriverservice.
How can we prevent code in the Passenger context from having to have any knowledge about external domains?

Evented programming with Publish-Subscribe
A common way to implement communication between contexts is via the Publish-Subscribe pattern. In this model, a system will publish a message over a channel, bound to an operator. Other systems can then subscribe to messages bound to that operator in that channel. Systems that publish messages do not need to know about the implementation details of the systems that subscribe to these messages, and vice versa.
Let’s go rewrite our prior driver-hailing example in an evented manner, in which we use the wisper gem to invert dataflow between our collaborating objects:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| # —————————– | |
| # Passenger (Experience) Domain | |
| # —————————– | |
| module Passenger | |
| # app/domains/passenger/find_driver_match.rb | |
| class FindDriverMatch | |
| include Wisper::Publisher | |
| def call(passenger, ride_requirements) | |
| # Publishes the event (a fact), but lets someone else do the rest of the hard work. | |
| broadcast("passenger_ride_requested", { | |
| ride_requirements: ride_requirements, | |
| passenger: passenger | |
| }) | |
| end | |
| end | |
| # A class devoted to handling incoming events from the Routing domain. | |
| # Handlers are added to specific events as-needed from within this (Passenger) domain. | |
| # | |
| # app/domains/passenger/routing_event_handler.rb | |
| class RoutingEventHandler | |
| def self.routing_driver_notified | |
| # Inform the passenger that the driver is on their way | |
| Passenger::SendDriverArrivalNotification.new.call(passenger, driver) | |
| end | |
| def self.routing_no_driver_found | |
| # Inform the passenger that no driver is available at this time. | |
| Passenger::SendRideUnavailableNotification.new.call(passenger) | |
| end | |
| end | |
| end | |
| # ————– | |
| # Routing Domain | |
| # ————– | |
| module Routing | |
| # A service class devoted to sending a notification or text to the driver and | |
| # acknowledging that they are on their way to the passenger. | |
| # | |
| # app/domains/routing/notify_driver.rb | |
| class NotifyDriver | |
| include Wisper::Publisher | |
| def call(driver, passenger) | |
| # … | |
| # Perform some Routing related code that notifies the driver's mobile device | |
| # and sends them on their way | |
| # … | |
| broadcast("routing_driver_notified", driver: driver, passenger: passenger) | |
| end | |
| end | |
| # Lightweight notification class that broadcasts the event that a driver is not available. | |
| class NoDriverFound | |
| include Wisper::Publisher | |
| def call(passenger) | |
| broadcast("routing_no_driver_found", passenger: passenger) | |
| end | |
| end | |
| # A class devoted to handling incoming events from the Passenger domain. | |
| # Handlers are added to specific events as-needed from within this (Routing) domain. | |
| # | |
| # app/domains/routing/passenger_event_handler.rb | |
| class PassengerEventHandler | |
| # Handles the event appropriately with domain-specific code. | |
| # The method name here corresponds with the name of the event. | |
| def self.passenger_ride_requested(payload) | |
| driver = Routing::FindDrivers.new(payload[:passenger]).call | |
| .select { |d| d.meets?(payload[:ride_requirements]) && d.matches_some_deeply_specific_thing? } | |
| .sample | |
| if driver | |
| Routing::NotifyDriver.new.call(driver, payload[:passenger]) | |
| else | |
| Routing::NoDriverFound.new.call(payload[:passenger]) | |
| end | |
| end | |
| end | |
| end | |
| # The app is configured to hook up a subscriber to the "passenger_experience_ride_requested" event | |
| # config/initializers/domain_event_subscriptions.rb | |
| Wisper.subscribe(Passenger::FindDriverMatch, scope: Routing::PassengerEventHandler) | |
| Wisper.subscribe(Routing::NotifyDriver, scope: Passenger::RoutingEventHandler) |
In this world, the handler code for the incoming passenger request to find a driver simply broadcasts a passenger_ride_requested event. It trusts that when it fires its event, the appropriate handler will pick up the workload after the event is fired. It does not concern itself with any Routing-related code on the other side of event publication.
Similarly, the data flow back from the Routing context does not need to know anything about the side effects needed in the Passenger context. The facts about the changes in the Routing context (routing_no_driver_foundor routing_driver_notified) are enough to inform the outside world to know how to react to it. The Passenger context simply subscribes to the facts it needs to know from the Routing side of the world, and acts accordingly.
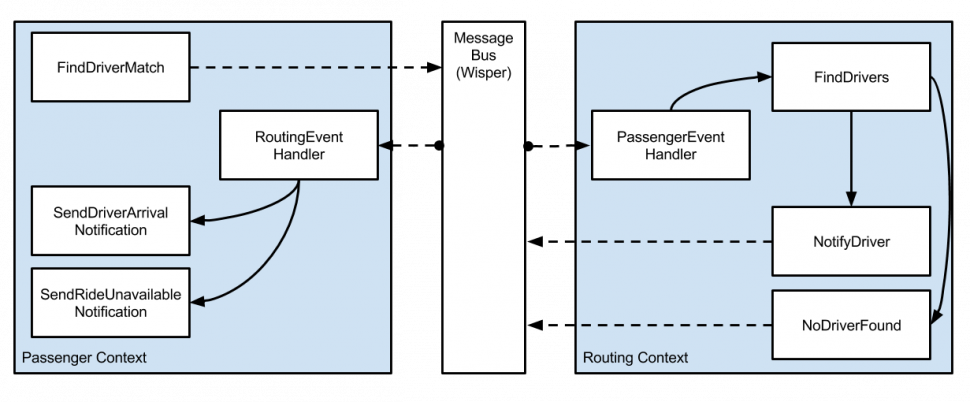
In the event-driven world, we simply publish facts about the system as it changes. Contrast this with the prior example which had a heavy dose of imperative programming logic which tends to couple our systems together and make our code brittle.
With the introduction of publish-subscribe patterns, we can develop clean breaks between different contexts of our systems — leading to loosely-coupled outcomes, and perfect for breaking up our large monolithic app into several different systems!
Do I really need all this complexity?
Adding evented abstractions will add extra complexity to your application. Consider if this approach is essential to your system yet. If you have a simple app – this pattern will be overkill for you.
Complex systems in complex domains need more organization patterns to allow them to scale. If your app is toppling under its own weight and domain code is highly coupled with other domain code – the evented approach may be worth considering for you!
This is all synchronous – for now
Even though it appears like we are using a message bus with asynchronous behaviors, in reality this is all performed synchronously under the hood, within the same thread. This may be a good thing for your app, if all you want to do is change the manner in which information is organized, hidden, and flowing under the hood.
However, by moving to this pub/sub model, we now have the ability to decouple the actual work of each subscriber into its own process. What if we wanted to scale our systems so that different processes in our infrastructure could handle that workload?
Asynchronous events with ActiveJob
We can go one step further and make our events run asynchronously where one process fires an event and another process is spun up to handle the event. Doing so has the advantage of decreasing the response time per request, since the amount of work to do is divided up among multiple processes. Dividing up work between processes between domain boundaries also enforces more concrete barriers between our contexts.
Fortunately for us, Wisper has an easy way of giving this to us for free. With the introduction of the wisper-activejob gem, the Wisper gem will enqueue event subscribers as ActiveJob-compatible jobs, allowing you to use a job queue like Sidekiq, Resque or DelayedJob to do the work. This is as simple as including the gem, and attaching an async: true flag to each subscription call.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| # The app is configured to hook up a subscriber to the | |
| # "passenger_experience_ride_requested" event | |
| # config/initializers/domain_event_subscriptions.rb | |
| Wisper.subscribe( | |
| Passenger::RideRequested, | |
| scope: Routing::PassengerEventHandler, | |
| async: true | |
| ) | |
| Wisper.subscribe( | |
| Routing::NotifyDriver, | |
| scope: Passenger::RoutingEventHandler | |
| async: true | |
| ) |
Well that was easy! Now, when a publisher broadcasts an event, a job will be enqueued for each handler that subscribes to said event — allowing you to scale out your system across your infrastructure!
Well, not so fast! We have one more very important discussion to have here, and it has to do with the complexities of building distributed systems.
The joys and pains of building a distributed system
Big win: speed & scalability
By splitting out domain logic into cohesive units, we’ve just designed our systems to farm out their workloads to a greater scalable number of workers. Imagine if you had a web request thread that would take 500ms to return, but 150ms of that time was spent doing a round trip to a different service. By decoupling that work from the main request thread and moving it to a background job – we’ve just sped up the responsiveness of our system for our end user, and we know that studies have shown that page speed performance equals money.
Additionally, making our application calls asynchronous allows us to scale the number of processing power we allocate to our system. We now have the ability to horizontally scale workers according to the type of job, or the domain they are working from. This may result in cost and efficiency savings as we match processing power to the workload at hand.
Big challenge: dealing with asynchronous data flows
Once things go async, we now have a fundamentally different data design. For example, say you implemented an HTTP API endpoint that performed some action in the system synchronously. However, now you’ve farmed out the effects of the action to background processes through domain events. While this is great for response times, you’ve now no longer got the guarantees to the caller that the desired side effect has been performed once the server responds back.
Asynchronous polling
An option is to implement the Polling pattern. The API can return a request identifier back to the caller on first call, with which which the caller can now query the API for the result status. If the result is not ready, the API service will return with a Nack message, or negative Ack, implying that the result data has not arrived yet. As soon as the results in the HTTP API are ready, the API will correctly return the result.
Pub/Sub all the way down
Another option is to embrace the asynchronous nature of the system wholly and transition the APIs to event-driven, message-based systems instead. In this paradigm, we would introduce an external message broker such as RabbitMQ to facilitate messages within our systems. Instead of providing an HTTP endpoint to perform an action, the API service could subscribe to a domain event from the calling system, perform its side effect, then fire off its own domain event, to which the calling system would subscribe to. The advantage of this approach is that this scheme makes more efficient use of the network (reducing chattiness), but we trade off the advantages of using HTTP (the ubiquity of the protocol, performance enhancements like layered caching).
Browser-based clients can also get in on the asynchronous fun with the use of WebSockets to subscribe to server events. Instead of having a browser call an HTTP API, the browser could simply fire a WebSocket event, to which the service would asynchronously process (potentially also proxying the message downstream to other APIs with messages) and then responding via a WebSocket message when the data is done processing.
Big challenge: data consistency
When we choose an asynchronous evented approach, we now have to consider how to model asynchronous transactions. Imagine that one domain process charges a user’s credit card with a third party payment processor and another domain process is responsible for updating it in your database. There are now two processes updating two data stores. A central tenet in distributed systems design is to anticipate and expect failure. Let’s imagine any of the following scenarios happens:
- An Amazon AWS partial outage takes down one of your services but not the other.
- One of your services becomes backed up due to high traffic, and no longer can service new requests in a timely manner.
- A new deployment has introduced a data bug in a downstream API that your teams are rushing to fix, but will requiring manual reconciling with the data in the upstream system.
How will you build your domain and data models to account for failures in each processing step? What would happen if you have one operation occur in one domain that depends on data that has not yet appeared in another part of the system? Can you design your data models (and database schema) to support independent updates without any dependencies? How will you handle the case when one domain action fails and the other completes?
First approach: avoid it by choosing noncritical paths to decouple, first
If you are implementing an asynchronous, evented paradigm for the first time, I suggest you carefully begin decoupling boundaries with domain events only for events that lie outside the critical business domain path. Begin with some noncritical aspect of the system — for example, you may have a third party analytics tracking service that you must publish certain business events to. That would be a nice candidate to decouple from the main request process and move to an async path.
Second approach: enforce transactional consistency within the same process/domain boundary
Although we won’t discuss specifics in this article, if you must enforce transactional consistency in some part of your system (say, the charging of a credit card with the crediting of money to a user’s account) then I suggest that you perform those operations within the same bounded context and same process, leaning on transactional consistency guarantees provided by your database layer.
Third approach: embrace it with eventual consistency
Alternatively, you may be able to lean on “eventual consistency” semantics with your data. Maybe it’s less important that your data squares away with itself immediately — maybe it’s more important that the data, at some guaranteed point in time — eventually lines up. It may be OK for some aspect of your data (e.g. notifications in a news feed) and may not be appropriate for other data (e.g. a bank account balance).
You may need to fortify your system to ensure that data eventually becomes consistent. This may involve building out the following pieces of infrastructure.
- Messages need to be durable — make sure your job enqueuing system does not drop messages, or at least has a failure mode to re-process them when (not if!) your system fails.
- Your jobs should be designed to be idempotent, so they can be retried multiple times and result in the correct outcome.
- You should easily be able to recover from bad data scenarios. Should a service go down, it should be able to replay messages, logs, or the consumer should have a queue of retry-able messages it can send.
- Eventual consistency means that you may need an external process to verify consistency. You may be doing this sort of verification process in a data warehouse, or in a different software system that has a full view of all the data in your distributed system. Be sure that this sort of verification is able to reveal to you holes in the data, and provide actionable insights so you can fix them.
- You will need to add monitoring and logging to measure the failure modes of the system. When errors spike, or messages fail to send (events fail to fire), you need to be alerted. Once alerted, your logging must be good enough to be able to trace the source and the data that each request is firing.
The scale of this subject is large and is under active research in the field of computer science. A good book to pick up that discusses this topic is Service-Oriented Design with Ruby on Rails. The popular Enterprise Integration Patterns book also has a great topic on consistency (and is accompanied by a very helpful online guide as well).
Event-driven Rails — a new paradigm
As we’ve discussed here, the usage of event-messaging paradigms can be powerful in decoupling responsibilities between different bounded contexts of the code in our large application. Since we previously have done the hard work of drawing the right boundaries around our systems — we simply have to add the necessary wiring steps to get them communicating with the right domain events.
Applications that are ready to move to the asynchronous model will see the benefit of increases responsiveness to production scale and pressure, but the tradeoff emerges when the system reveals itself to be a distributed system, and one needs to begin designing for a distributed system.
There’s no right or wrong way to go about this – implement an incremental approach and see how it goes. First try to fire off synchronous domain events with a framework like Wisper. If that works for you, then see if you feel good about moving each of those domain event handlers to a background job with ActiveJob. Be extra careful about data guarantees and failure modes, and design your systems to account for them.
How has this worked out for you? Let us know on Twitter!
Andrew Hao
Andrew is a design-minded developer who loves making applications that matter.